Innovation: Efficient Text Blocks for Web Forms
Summary
After the subject matter expert has approved the text change, the new content appears automagically on the online service page as fast as the CI/CD pipeline allows. No programmer or tester involved.
How this can be achieved is explained here with a simple proof of concept applying basic principles of software engineering. While this proof of concept is based on Confluence and Angular because of their widespread use, the underlying approach can easily be implemented on other platforms due to its simplicity.
When Does Text Matter?
Text is a major part of online services such as applying for a consumer loan or for a resident parking permit. Texts describe what the service offers, what data the customer has to provide, how privacy will be protected and so on.
It may require a lot of time and effort to keep texts up to date, for example with laws and regulations, new customer insight and changing market conditions.
In particular an efficient handling of text does matter for text-intensive online services that
- are important to the service provider: Major failures can cause severe reputational damage or large financial losses.
- require a lot of effort to develop and maintain: The team usually consists of more than 10 people.
- are planned to have a long lifespan, typically many years.
The following software engineering principles help to master the texts of such services:
- Avoid manual redundancy
- Capture the logical essence
- Automate boring tasks
- Take advantage of synergies
The subsequent sections explain each of these points.
Avoiding Manual Redundancy
Redundancy is harmful, if it is created and maintained manually. In this case it is only a matter of time until things will become inconsistent. Inconsistency is the highway to hell for large amounts of text.
In order to avoid manual redundancy,
- specify a text only in one place in a format that is complete and clear enough for using this text in many different contexts (see Capturing the Logical Essence)
- use tools to propagate text changes to specification documents, web site code, PDF output, test parameters etc. (see Automate Boring Tasks)
Capturing the Logical Essence
A text block is not just a bunch of words, it has
- a unique identifier that allows you to reference the text block
- a sharp boundary that separates the text from the rest of the world
- a logical structure consisting of headings, paragraphs, lists, links and so on.
For readers as well as for tools it is important to not hide the logical structure in a prose similar to Victorian novels but to make it explicit. This can be achieved by using a markup language like Markdown or HTML. Whatever format you choose, it should be supported by
- editors suited for subject matter experts
- tools that make it easy to read, write and transform this format
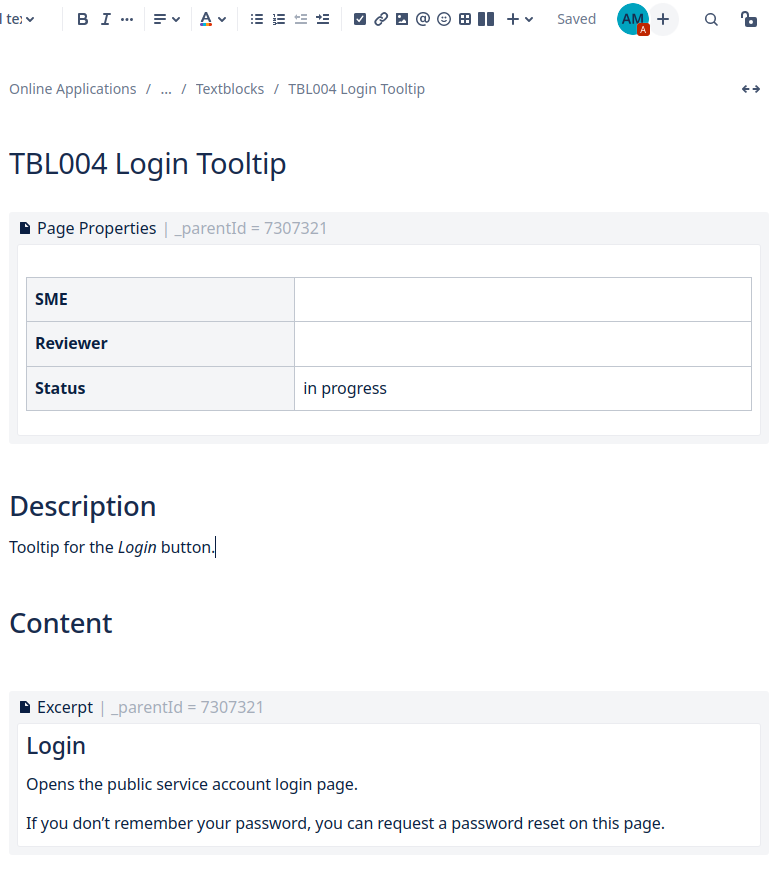
In the proof of concept each text block is a Confluence page (see screen shot above), since pages offer many features for handling text:
- Confluence provides an editor that makes it easy to specify the logical text structure.
- Internally Confluence stores the pages as HTML, so that you can use many tools for further text processing.
- Meta data enable you to manage text blocks easily and to configure a Confluence workflow for text review and approval. The above screen shot shows some of the meta data within the Page Properties macro: SME (subject matter expert), reviewer and status of the text block. In addition the page is labeled as “textblock”.
- Confluence macros are available to seamlessly include a text block into specification documents (Excerpt macro and Excerpt Include macro). So you can specify a text in a single place and reuse it across the specification while Confluence handles the dependencies for you.
- Confluence offers a REST API and a Python package to access the text blocks with tools for the automation of boring tasks.
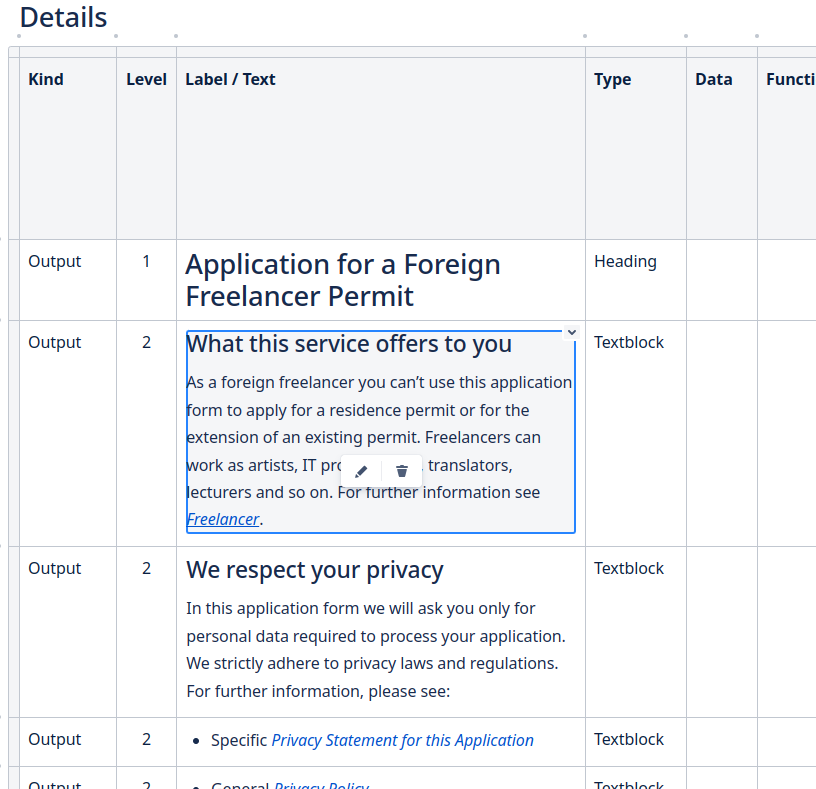
Automating Boring Tasks
Using a specified text in implementation or testing requires schematic routine tasks: extract the text from the specification, reformat it, integrate it into source code or test scripts, review and test your results.
While such schematic routine tasks are boring and error-prone for humans, they are well suited for computers. You just need to apply your programming skills not only to the services you build but also to the development process itself.
Python Script
A simple Python script extracts text blocks from Confluence using Atlassian’s Confluence package. The script is generously commented in order to make it comprehensible for programmers who are not proficient in Python.
The extraction script provides text blocks in several formats:
- HTML for Angular component templates
- Plain text for Angular tool tips
- Excel for review
A programmer who wants to use a text block in his Angular code just needs to insert a macro at the right place with the text block id as parameter: The rest is done automatically by the Angular ahead-of-time (AOT) compiler.
Using Text Blocks in Web Pages
The next sceen shot shows a demo implementation of an online service’s introductory page. How all the text content of this page is provided from Confluence by using extraction script and macro is described in the following sections.
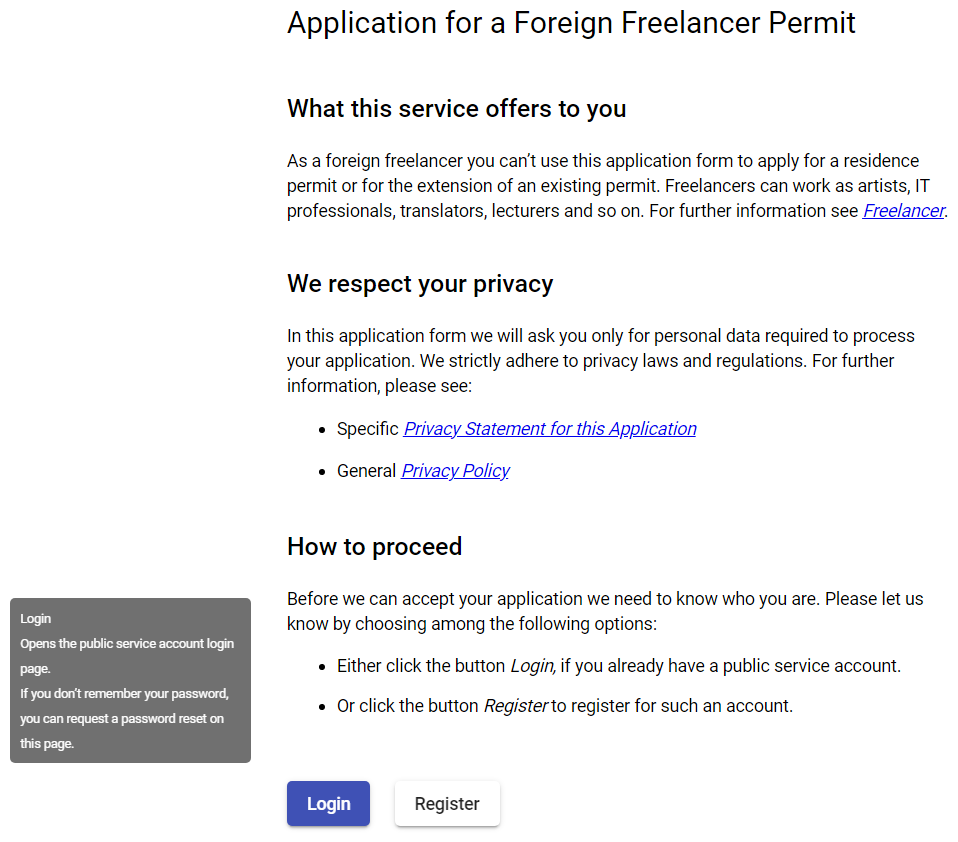
The code below defines the introduction page of the “Application for a Foreign Freelancer Permit” (app.component.html). Some of the specified text blocks can be found here as app-tbl* elements representing Angular components with the text block content as component template.
<div>
<div>
<h1>{{title}}</h1>
</div>
<app-tbl001002></app-tbl001002>
<app-tbl001></app-tbl001>
<app-tbl001001></app-tbl001001>
<app-tbl002></app-tbl002>
<app-tbl003></app-tbl003>
<div class = "button-row">
<button mat-raised-button
color = "primary"
matTooltip = {{loginTooltip}}
matTooltipClass = "matTooltipLinebreak"
aria-label = "Login button with tooltip">
Login
</button>
<button mat-raised-button
matTooltip = {{registerTooltip}}
matTooltipClass = "matTooltipLinebreak"
aria-label = "Register button with tooltip">
Register
</button>
</div>
</div>Here as an example the text block component tbl001002.component.ts defining the element app-tbl001002:
import { Component, OnInit } from '@angular/core';
import { includeText } from '../includeText';
@Component({
selector: 'app-tbl001002',
//templateUrl: './tbl001002.component.html',
template: includeText("TBL001002"),
styleUrls: ['./tbl001002.component.css']
})
export class Tbl001002Component implements OnInit {
constructor() { }
ngOnInit(): void {
}
}The developer replaced the default template URL with a template filled by the includeText macro with the content of text block TBL001002.
IncludeText Macro
And here the definition of the includeText macro. All the work is done by the return statement:
// includeText.ts
import { texts } from '../../texts/texts'; // text definitions
/**
* AOT macro for including reusable text blocks
* @param id Identifier of the text to include
* @return Text to include; unknown id returns 'undefined' value at build time
*/
export function includeText(id: string): string {
return texts[id];
}Actually at the time of writing, an AOT macro can consist only of a single statement – the return statement.
The includeText macro uses the dictionary “texts” defined in texts.ts. This file is generated by the above Python script:
// GENERATED CODE: DO NOT CHANGE MANUALLY!
export const texts: { [key: string]: string } =
{
"TBL001":
"<div tb_id=\"TBL001\" title=\"Privacy Statement\"><h2>We respect your privacy</h2><p>In this application form we will ask you only for personal data required to process your application. We strictly adhere to privacy laws and regulations. For further information, please see:</p></div>",
"TBL001001":
"<div tb_id=\"TBL001001\" title=\"Privacy Statement\"><ul><li><p>Specific <a href=\"https://www.to_be_defined.html\"><em>Privacy Statement for this Application</em></a></p></li></ul></div>",
"TBL001001_plain":
`- Specific Privacy Statement for this Application
`,
...
}The includeText macro can be called wherever a string is allowed. In app.component.ts the text for login and register button are provided by calling the includeText macro with appropriate text block ids. Here the plain format of the text blocks is used instead of the html format:
/* Demo: reusable textblocks
*/
import { Component } from '@angular/core';
import { includeText } from './includeText';
@Component({
selector: 'app-root',
templateUrl: './app.component.html',
styleUrls: ['./app.component.css']
})
export class AppComponent {
title = 'Application for a Foreign Freelancer Permit';
loginTooltip = includeText("TBL004_plain");
registerTooltip = includeText("TBL005_plain");
}Taking Advantage of Synergies
Development and maintenance of online services is a complex task requiring close cooperation across many disciplines. This means that a small change like introducing text blocks as a means of specification can have the potential to improve many other aspects of your project, if you take advantage of synergies.
Here some examples:
- Optimize testing
- On the one hand the text block tools have to be tested to ensure they work as intended.
- One the other hand such unit tests make it obsolet to test whether the texts displayed on the web site have exactly the same content as the specified texts.
- It remains to be tested that a specific text block is shown at the right place under the right condition.
- Usually these requirements are much less subject to change than the text block content.
- With unique ids it is no longer necessary for a text script to know the text content to find out where a text is located. Instead it can look for the text block’s id. The exctraction script generates the text block id into the div element that encloses the text block content.
Example:
<div tb_id=\”TBL001\” title=\”Privacy Statement\”>
- Tracing text usage
- Since each text has a unique id you can trace the usage of a text throughout the system (specification documents, source code, text scripts and so on).
- This makes it easier to analyse the impact of text changes: In what contexts do you use a particular text block? Will the intended text change be compatible with all the contexts where the text is currently used?
- Reduce time to market for text changes
- Texts blocks can be used to reduce the time to market for text changes drastically (provided that you adapt the tool chain of your project accordingly):
- After subject matter experts have edited a text block and reviewed / approved the change, the tool chain automatically extracts the new version from the specification and integrates it into the source code.
- Meanwhile developers and testers can spend their time with tasks that are more challenging and not prone to automation.
- Texts blocks can be used to reduce the time to market for text changes drastically (provided that you adapt the tool chain of your project accordingly):
What next?
If you would like to apply this approach to your own project:
- You should agree with the stakeholders on a text management process: triggers for text changes, standards for a customer friendly language, reviews, approvals etc.
- Concerning the extraction of text blocks from your Content Management System, you can take the above script as a starting point. However you should add some exception handling for robustness and implement unit tests to make sure it works as intended.
Perhaps this little example has whetted your appetite for more efficiency through software engineering in your project? In case you need some advice please feel free to contact me. I would also be glad to receive any feedback on the approach presented here.
Innovation: Efficient Text Blocks for Web Forms Read More »