PDF-Formulare analysieren mit Python
Wozu ist das gut?
Wenn der Öffentliche Sektor seine Leistungen online anbieten will, gibt es meist schon entsprechende Antragsformulare in Papierform oder als Datei zum Herunterladen. Gedruckte und heruntergeladene Variante basieren in der Regel auf einer Vorlage im Portable Document Format (PDF). PDF-Dateien sind daher häufig ein Ausgangspunkt beim Entwurf von digitalen Antragsstrecken.
Allerdings ist es mühsam, aus PDF-Dateien diejenigen Informationen herauszuklauben, die man für die Spezifikation einer Antragsstrecke braucht, z.B. :
- Gliederung des Formulars in Abschnitte
- Eingabefelder mit ihren Bezeichnungen und erlaubten Eingaben
- Zusatzinformationen, die beim korrekten Ausfüllen helfen sollen
In diesem Beitrag beschreibe ich ein Python-Skript, das einem langweilige Routineaufgaben bei der Analyse von PDF-Dateien abnimmt.
Die Analyse erfolgt schrittweise
Die Analyse eines PDF-Formulars erfolgt in mehreren Schritten:
import json
from pathlib import Path
# Konfiguration einlesen
with open("config.json", "r") as f:
config = json.load(f)
pdf_dateien = Path(config['input_dir']).glob('**/*.pdf')
for pdf_datei in pdf_dateien:
print("Analysiere: ", pdf_datei)
pages = Text_extrahieren(pdf_datei)
data, columns = Text_zu_Tabelle(pages)
df = Felder_identifizieren(data, columns)
df = Abschnitte_identifizieren(df)
df = Zeilen_klassifizieren(df)
excel_datei = Path(f'{pdf_datei}.xlsx')
print("Ergebnis: ", excel_datei, "\n")
Dataframe_schreiben(df, excel_datei)Das Skript erwartet die zu analysierenden PDF-Dateien in einem Verzeichnis, das man in der Konfigurationsdatei config.json als Parameter input_dir angeben kann. Die Python-Bibliothek pathlib ermöglich es, unabhängig von den Konventionen des verwendeten Betriebssystems (Windows, Linux usw.) über die PDF-Dateien zu iterieren und sie in folgenden Schritten zu analysieren:
- Texte aus dem PDF-Formular extrahieren und in eine tabellarische Form bringen, wobei die Texte seitenweise von rechts oben nach links unten ausgewertet werden
- Bedeutung der Texte analysieren
Beim zweiten Schritt nutzt man aus, dass PDF-Formulare oft eine Struktur aufweisen, die etwas über die Bedeutung der extrahierten Texte aussagt:
- Überschriften von Formular-Abschnitten können durchnummeriert sein, entweder mit Ziffern oder mit Buchstaben
- Felder können ebenfalls fortlaufend nummeriert sein
Hier ein Beispiel, in dem man Überschriften und Eingabefelder an ihrer fortlaufenden Nummerierung erkennen kann:
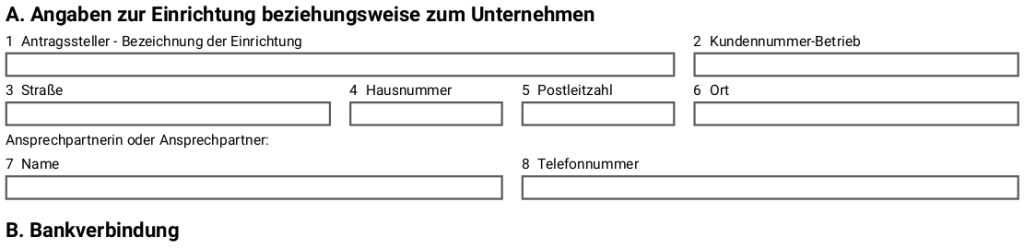
Je PDF-Formular speichert das Skript die Analyse-Ergebnisse in einer Excel-Datei, deren Name sich aus dem der PDF-Datei plus angehängtem Suffix “.xlsx” ergibt:
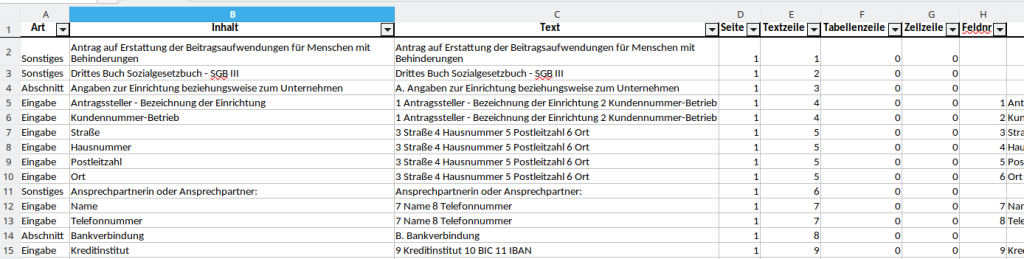
Die erste Spalte gibt an, wie das Skript den Text klassifiziert hat, der in der Spalte “Inhalt” steht:
- Abschnitt: Überschrift eines Abschnitts
- Eingabe: Bezeichnung eines Eingabefelds
- Sonstiges: Text, der nicht genauer klassifiziert werden konnte
Die Spalte “Text” enthält zum Vergleich die originale Zeile, die aus dem PDF-Formular extrahiert wurde. Man kann sie ebenso wie die folgenden Spalten dazu verwenden, Fehlern bei Extraktion und Klassifikation auf die Spur zu kommen.
Beim Extrahieren aus PDF hilft ein Klempner
Für Python gibt es mehrere Bibliotheken zum Auswerten von PDF-Dateien. In diesem Skript habe ich pdfplumber verwendet. So kann man auch ohne PDF-Spezialwissen Text aus PDF-Dateien extrahieren. Dabei wird der extrahierte Text seitenweise ausgelesen, auch der Text, der in Tabellen enthalten ist:
from operator import itemgetter
import pdfplumber
def check_bboxes(word, table_bbox):
"""
Prüft, ob word innerhalb von table_bbox liegt.
table_bbox ist der Rahmen (bounding box) um die Tabelle.
"""
l = word['x0'], word['top'], word['x1'], word['bottom']
r = table_bbox
return l[0] > r[0] and
l[1] > r[1] and
l[2] < r[2] and
l[3] < r[3]
def Text_extrahieren(pdf_datei):
"""
Extrahiert Text und Tabellen aus einem PDF-Formular.
IN:
pdf_datei Pfad der zu analysierenden PDF-Datei
RETURN:
Liste von Seiten, die Listen von Zeilen enthalten
'text' = Zeile mit Text außerhalb von Tabellen
'table' = Zeile mit Text innerhalb von Tabellen
"""
with pdfplumber.open(pdf_datei) as pdf:
# Seiteninhalte extrahieren
pages = []
for page in pdf.pages:
# Tabellen mit ihren Begrenzungen extrahieren
tables = page.find_tables()
table_bboxes = [i.bbox for i in tables]
tables = [{'table': i.extract(),
'top': i.bbox[1]
} for i in tables
]
# Wörter außerhalb von Tabellen ermitteln
non_table_words = [
word for word in page.extract_words()
if not any([
check_bboxes(word, table_bbox)
for table_bbox in table_bboxes])]
# Zeilen der Seite in Liste zusammenstellen
lines = []
for cluster in pdfplumber.utils.cluster_objects(
non_table_words + tables,
itemgetter('top'),
tolerance = 5):
if 'text' in cluster[0]:
lines.append(' '.join(
[i.get('text', '')
for i in cluster
]))
elif 'table' in cluster[0]:
lines.append(cluster[0]['table'])
# Zeilen der neuen Seite hinzufügen
# zur Liste der Seiten
pages.append(lines)
return(pages)Das Ergebnis pages ist eine Liste von Seiten. Für jede Seite enthält es eine Liste der darin gefundenen Zeilen. Diese geschachtelte Liste wird später in eine Tabelle umgewandelt und bei der weiteren Analyse angereichert.
Das vollständige Skript findet man im folgenden Kapitel.
Quelldateien
Das Python-Skript wurde hier mit dem Suffix “.txt” statt “.py” bereitgestellt, um Berechtigungsprobleme zu vermeiden.
Hier requirements.txt mit den verwendeten Bibliotheken:
Die Konfigurationsdatei config.json hat folgenden Inhalt:
{
"input_dir" : "./pdf_dir"
}PDF-Formulare analysieren mit Python Read More »