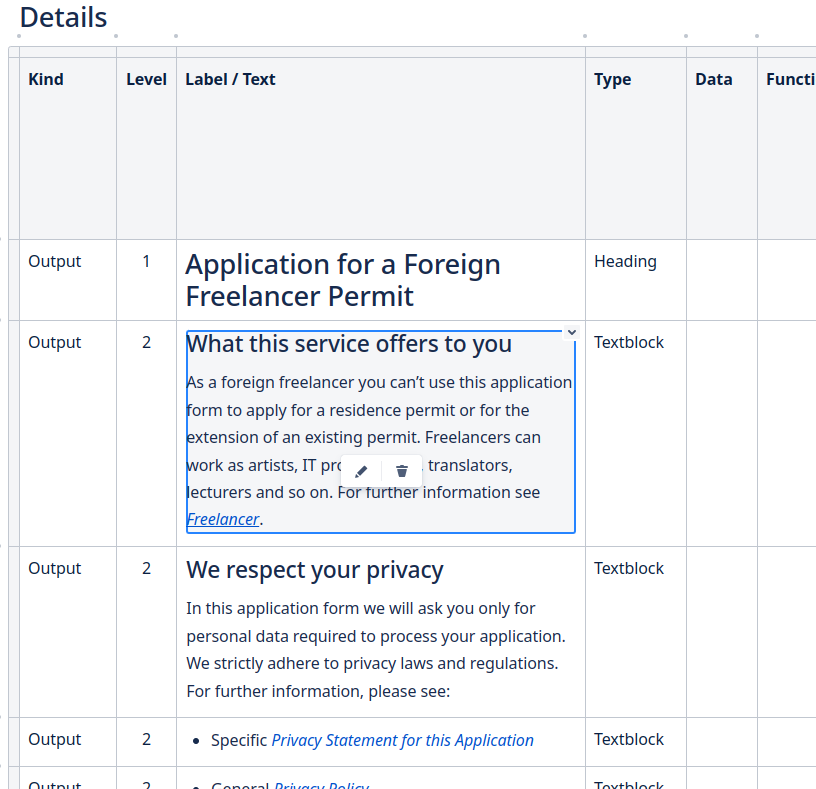
Die Innovation
Verfahren aus der Genom-Analyse habe ich eingesetzt, um Redundanzen im komplexen Fachkonzept eines Großprojekts aufzuspüren. Die Analyse-Ergebnisse ermöglichten es dem Projekt, die Redundanzen zu priorisieren und ihre schrittweise Bereinigung zu planen. Diese Reduzierung hat dazu beigetragen, die Time-to-Market neuer fachlicher Anforderungen zu halbieren.
Das Problem
In diesem Projekt gab es viele Ursachen für eine lange Time-to-Market neuer Anforderungen. Mit der “Genom-Analyse” des Fachkonzepts wollte man die beiden folgenden Ursachen entschärfen
- Beim Test neuer Releases tauchten oft so viele Fehler auf, dass das Team sich mächtig ins Zeug legen musste, um den Releasetermin nicht zu gefährden.
- Auch kleine fachliche Änderungen konnten unverhältnismäßig aufwändig sein. Bei der Releaseplanung musste man entweder das System außerordentlich gut kennen oder die anstehende Änderung sehr sorgfältig analysieren, um nicht später bei der Umsetzung eine böse Überraschung zu erleben.
Eine Ursachenforschung ergab, dass diese beiden Probleme oft dieselbe Ursache hatten: Redundante Passagen im Fachkonzept wurden auf inkonsistente Weise geändert. Die Fachliche Chefdesignerin des Projekts vermutete, dass in den Hunderten von Seiten akribischer Fachkonzeptprosa noch viele verborgene Redundanzen auf ihre Chance lauerten, den Adrenalinspiegel des Teams in die Höhe zu treiben.
Sie bat mich daher um eine Redundanzanalyse des Fachkonzepts:
- Welche Textblöcke sind redundant?
- Welchen Text enthalten die verschiedenen Varianten?
- An welchen Stellen kommt ein redundanter Textblock jeweils vor?
- Wie ähnlich sind sich die verschiedenen Varianten eines Textblocks? Am besten wäre hier eine Kennzahl, die in die Priorisierung der Redundanzbereinigung einfließen kann.
Wir diskutierten diese Aufgabe eine Weile und erfuhr folgende Details über die Entstehung der gefürchteten Redundanzen:
- Ein bestimmter Verarbeitungsschritt soll auch in einer weiteren Verarbeitung durchgeführt werden, z.B. wird eine Intervallberechnung für die Krankenversicherung auch für die Pflegeversicherung benötigt.
- Nun kopiert man den betreffenden Abschnitt und passt die Kopie an die Besonderheiten der Pflegeversicherung an:
- Vor allem tauscht man dabei die im Text referenzierten Attribute des fachlichen Datenmodells aus, denn die Daten zur Pflegeversicherung sind in speziellen Pflegeversicherungs-Attributen gespeichert.
- Es kann aber auch sein, dass die Verarbeitung der Pflegeversicherung leicht derjenigen der Krankenversicherung abweicht und der kopierte Abschnitt entsprechend überarbeitet werden muss.
- Wenn die Kopien eines redundanten Abschnitts geändert werden, z.B. wegen einer neuen fachlichen Anforderung, kann es vorkommen,
- dass sich die überarbeiteten Kopien am Ende unterscheiden, etwa weil verschiedene Personen die Änderungen parallel durchgeführt haben, um sie schneller abschließen zu können oder
- dass man Kopien übersieht, die daher auf dem alten Stand bleiben.
Die Lösung
Als Biologe ist mir eine Analogie ins Auge gesprungen zwischen dem redundanten Fachkonzept und dem Farbsehen beim Menschen. Und schon hatte ich den Schlüssel für die Lösung.
Spoiler alert: Im nächsten Absatz lüfte ich das Geheimnis. Wer den Zusammenhang selbst ausknobeln möchte, sollte daher nicht gleich weiterlesen.
Ein Mensch hat für das Farbsehen normalerweise drei Sehpigmente, deren Absoptionsmaximum im roten, grünen beziehungsweise blauen Bereich des Lichtspektrums liegt. Das rote und das grüne Sehpigment ähnlich einander stark: Tatsächlich zeigten genetische Analysen, dass zunächst das Gen für das grüne Sehpigment dupliziert wurde, genauer gesagt das Gen für den Proteinanteil des Pigments. Durch diese Mutation entstanden zwei identische Versionen desselben Pigments. Die beiden Kopien haben sich im Lauf einiger Jahrmillionen durch zusätzlich Mutationen immer weiter auseinander entwickelt. Also ähnlich wie die redundanten Abschnitte im Fachkonzept. Aufgeklärt hat man diese Evolutionsgeschichte durch die Analyse der Genome verschiedener Tierarten, insbesondere von Primaten. Ich brauchte also “nur” eine Art von “Genom-Analyse” für das Fachkonzept zu machen.
Wahl des Werkzeugs
Welches Werkzeug ich für die Redundanzanalyse am besten verwenden sollte, lag also auf der Hand:
- Bei Genomanalysen werden vor allem Python und seine mächtigen wissenschaftlichen Bibliotheken eingesetzt.
- Python verwendet man auch gern für Textanalysen.
- Python kann gut mit regulären Ausdrücken umgehen, wie ich sie brauchen würde, um irrelevante Teile des Fachkonzepts auszublenden und Datenmodell-Referenzen zu normalisieren (mehr dazu gleich).
- Python eignet sich als Interpreter-Sprache prima für Projekte, bei denen man zwar die grobe Zielrichtung kennt, sich aber den genauen Weg erst explorativ erarbeiten muss.
Python gehörte auch zur Infrastruktur meines Kunden und so konnte es losgehen. In den folgenden Abschnitten beschreiben ich Schritt für Schritt den Weg bis zur fertigen Redundanzanalyse.
Ausblenden irrelevanter Teile
Für die Redundanzanalyse musste man zunächst den Spezifikationstext aus dem UML-Modellierungswerkzeug exportieren, damit sich Python darüber hermachen konnte. Zuerst versuchte ich, aus dem Text die eigentliche fachlichen Verarbeitung zu extrahieren. Die Spezifikation war in purem Text ohne Formatierung verfasst und enthielt über die Beschreibung der fachliche Verarbeitung hinaus auch einführende Absätze als Einstiegshilfe für die Leser. Diese Absätze waren durch bestimmte Schlüsselwörter gekennzeichnet, sodass mein Python-Skript sie leicht von der weiteren Analyse ausschließen konnte.
Normalisierung der Datenmodell-Referenzen
Den restlichen Text spaltete das Skript in Absätze auf. In jedem Absatz suchte es nach Datenmodell-Referenzen, die durch typische Sonderzeichen zu erkennen waren, z.B. “#” als Trenner zwischen Klassen- und Attribut-Bezeichner. Diese Referenzen normalisierte das Skript, indem es die tatsächlichen Bezeichner durch die Standard-Bezeichner “Klassenname” und “Attributname” ersetzte.
Suche nach einem Maß für die Ähnlichkeit
Um redundante Abschnitte zu erkennen, musste das Skript Abschnitte paarweise vergleichen und ihre Ähnlichkeit mit einer normalisierten Maßzahl beziffern, die unabhängig vom Umfang der Abschnitte nur Werte zwischen 0 und 1 annimmt, wobei 1 für perfekte Übereinstimmung und 0 für kompletten Unterschied steht.
Ich stöberte in den Python-Bibliotheken und stieß schließlich auf eine Funktion zur Berechnung der “Levenshtein distance”, die auf der Anzahl von Einfügungen, Löschungen und Ersetzungen einzelner Buchstaben basiert, die man mindestens braucht, um den einen Partner des Vergleichspaars in den anderen umzuwandeln. Mit ähnlichen Abstandsmaßen ermittelt man in der Genom-Analyse, wie nahe zwei Individuen miteinander verwandt sind.
Experimente mit einem kleinen Ausschnitt des Fachkonzept lieferten vielversprechende Ergebnisse: Je höher die berechnete Ähnlichkeitszahl, um so ähnlicher war auch die fachliche Bedeutung.
Feinabstimmung der Ähnlichkeitsmessung
Umgekehrt traf das aber nicht immer zu: Manche Paare mit kleiner Ähnlichkeitszahl lagen inhaltlich näher beeinander als andere Paare mit hoher Ähnlichkeitszahl. Man sah auch sofort, dass es dafür zwei Ursachen gab:
- Synonyme
Zum einen wurden zwar unterschiedliche Wörter verwendet, diese hatten aber dieselbe Bedeutung. Ich ergänzte das Skript also durch eine Konfigurationsliste mit Synonymen und eine Vorverarbeitung, die verschiedene Wortvarianten durch eine Standard-Bezeichnung für den gemeinten Begriff ersetzte. - Füllwörter
Manche Vergleichspartner unterschieden sich in der Verwendung von Füllwörtern, die den Text mehr oder weniger weitschweifig machen, sich aber nicht auf den fachlichen Sinn auswirken. Daher löschte das Skript nun auch solche Füllwörter in einer weiteren Vorverarbeitung.
Nach diesen Ergänzungen lieferte das Skript beim paarweisen Vergleich einiger handverlesener Abschnitte plausible Ähnlichkeitszahlen, sodass einem flächendeckenden Vergleich nichts mehr im Wege stand.
Ermittlung maximal großer Ähnlichkeitsbereiche
Der erste große Analyse-Lauf lieferte eine riesige Menge von Ähnlichkeitszahlen, denn die Abschnitte waren oft sehr kurz – viele bestanden nur aus einer einzigen Zeile, manchen nur aus einem einzigen Wort.
Solche Mini-Abschnitte sind für die Suche nach fachlichen Redundanzen nicht zu gebrauchen. Daher erweiterte ich das Skript so, dass es direkt aufeinander folgende Abschnitte, die ein bestimmtes Maß an Ähnlichkeit überschritten, zu einem einzigen längeren Abschnitt zusammenfasste.
Nach ein paar Probeläufen mit verschiedenen Schwellwerten für das “Maß an Ähnlichkeiten” bekam ich schließlich vernünftige Ergebnisse und lies das Skript dann wieder auf das gesamte Fachkonzept los. Am Ende lieferte es eine große Tabelle (in Python ein dataframe mit paarweisen Vergleichen.
Redundanzcluster
Jetzt musste ich noch eine Möglichkeit finden, die Vergleichspaare übersichtlich aufzubereiten. Das Fachkonzept-Team wollte ja sehen, welche Redundanzen besonders “schlimm” waren, sodass man sie möglichst bald bereinigen konnte. Dazu musste man die paarweisen Vergleiche zu Redundanz-Clustern zusammenfassen. Mit einem zweiten Skript wurden aus den paarweisen Vergleichen Cluster von untereinander sehr ähnlichen Abschnitten extrahiert (mithilfe eines weiteren Schwellwert-Parameters). Für jeden dieser Cluster lieferte das Skript folgende Informationen:
- Eine eindeutige Cluster-Kennung
- Einen zufällig herausgepickten Vertreter mit dem Textinhalt, sodass man den fachlichen Sinn erkennen konnte
- Die Anzahl der Elemente des Clusters
- Eine mittlere Ähnlichkeitszahl, die als Mittelwert aus den Ähnlichkeitszahlen der paarweisen Vergleiche zwischen den Elementen der Clusters berechnet wurde
- Eine Kennzahl für die Redundanzbereinigung: je mehr Kopien und je umfangreicher die Abschnitte, um so größer die Kennzahl
Außerdem wurde eine Liste der Abschnitte erzeugt mit folgenden Informationen:
- Eine eindeutige Kennung für den Abschnitt
- Wo sich dieser Abschnitt im Fachkonzept befindet
- Der Text des Abschnitts
- Die Kennung des Clusters, zu dem der Abschnitt gehört
Manuelle Prüfung auf echte fachliche Redundanz
Beide Listen wurden dann in Excel geladen und dem Fachkonzept-Team zur Verfügung gestellt. Nun konnte die eigentliche Suche nach fachlichen Redundanzen beginnen. Dazu mussten Fachexperten prüfen,
- ob sich die Varianten eines Abschnitts nur zufällig ähnelten: das kam vor allem bei Clustern mit kürzeren Abschnitten vor,
- oder ob die Varianten eines Abschnitts aus fachlichen Gründen identisch sein sollten: nur in diesem Fall handelt es sich um eine echte fachliche Redundanz.
Hier ist eine weitere Analogie zur Genomanalyse interessant: In der Genetik bezeichnet man Gene als homolog, wenn sie wahrscheinlich einen gemeinsamen Ursprung haben, so wie die Gene für den roten und grünen Sehfarbstoff. Als homolog gelten Gene, die in mehr als 30 % ihrer Nukleotide übereinstimmen (Nukleotide sind quasi die Buchstaben des genetischen Texts).
Die fachlich redundanten Varianten eines Abschnitts könnte man also als “homolog” bezeichnen, während sonstige Ähnlichkeiten purer Zufall sind – oder handelt es sich vielleicht manchmal um einen Fall von “konvergenter Evolution”? Dabei entwickeln sich ähnliche Strukturen aus völlig verschiedenen Ursprüngen, z.B.
- unsere Linsenaugen und
- die Linsenaugen von Tintenfischen wie dem Octopus.
Die letzten gemeinsamen Vorfahren von uns und den Tintenfischen hatten nämlich kein Linsenaugen, höchstens ein paar lichtempfindliche Zellen.
Fazit
Dass ich bei der Redunanzanalyse des Fachkonzepts auf Analogien zur Genom-Analyse zurückgreifen konnte, hat mir Umwege erspart und die Analyse enorm beschleunigt, denn ich konnte mich aus einem wohlgefüllten Werkzeugkasten bedienen. Auf den Schultern von Riesen kann man eben weiter sehen, welche Art von Linsenaugen man hat.